
 Sample Submission Guidelines
Sample Submission GuidelinesWe use cookies to understand how you use our site and to improve the overall user experience. This includes personalizing content and advertising. Read our Privacy Policy
Accept Cookies

Over the last fifty years, a number of researchers have devoted themselves to the development of DNA sequencing technology. This time-scale has witnessed drastic changes, moving from short oligonucleotides to millions of bases, from single-gene sequencing to whole-genome sequencing, from short-read sequencing to long-read sequencing, and from first-generation sequencing to third-generation sequencing. The ‘chain-termination’ or dideoxy technique developed by Sanger in 1977 is one of the breakthroughs that forever changed the progress of DNA sequencing technology. While the first-generation sequencing only produces reads slightly less than one kb in length, the next-generation sequencing (NGS) sprung up such as Roche 454 and Illumina (massively parallel sequencing), greatly increased the amount of DNA in a single sequencing run. The third-generation sequencing techniques appeared, characterized by single-molecule, real-time and long-read. The most important among them are PacBio SMRT sequencing and nanopore sequencing. Among those techniques, nanopore sequencing is the most anticipated one to accomplish the gold standards. For a comprehensive understanding, please refer to the chapter titled "Principle of Nanopore Sequencing ".
Service you may intersted in
Resource
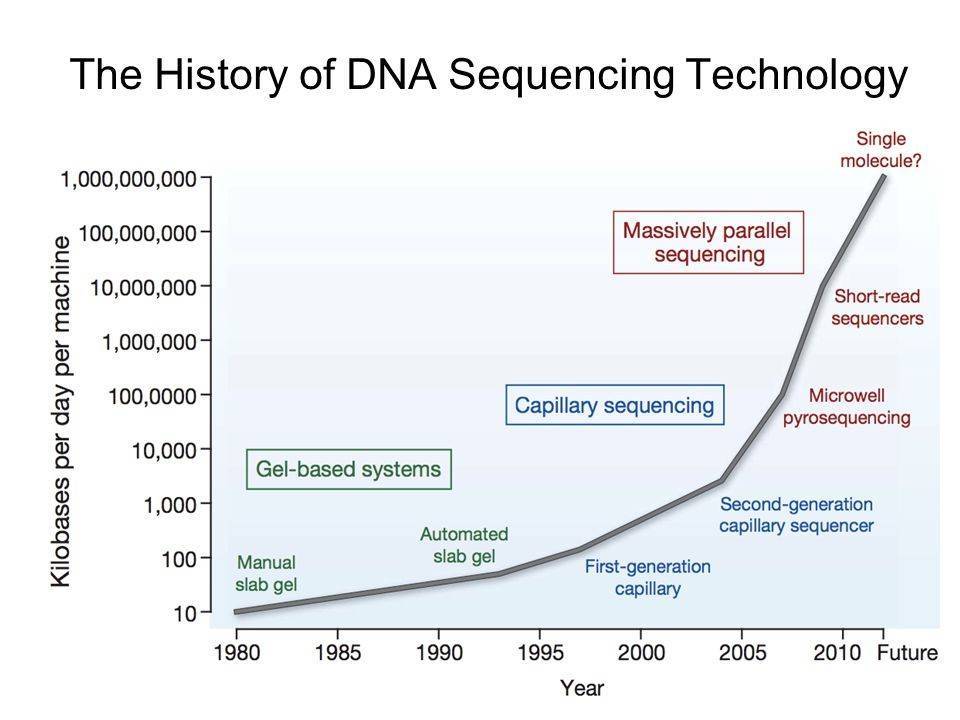 Figure 1. The history of DNA sequencing technology.
Figure 1. The history of DNA sequencing technology.
Oxford Nanopore Technologies (ONT) is the first nanopore sequencing-based company and has generated a lot of excitement over their nanopore platforms like MinIONTM, GridIONTM, and PromethIONTM. While MinIONTM is a small and portable device released in 2014, GridIONTM and PromethIONTM offer respectively 5 and 300 times the yield of MinIONTM. FlongleTM is an adapter for the MinIONTM and GridIONTM X5 sequencing devices, producing as much as 1.8 Gb data with headroom for over 3 Gb.
 Figure 2. Nanopore sequencing platforms at ONT.
Figure 2. Nanopore sequencing platforms at ONT.
A nanopore is a nano-scale hole. Nanopore platforms use pore-forming proteins to create pores in membranes (biological nanopores) or use nanopores fabricated from synthetic materials (solid-state nanopores). Oxford Nanopore platforms pass an ionic current through nanopores and measures the alterations in current when biological molecules pass through the nanopore or near it. The alterations are documented and translated to identify that molecule and base modification.
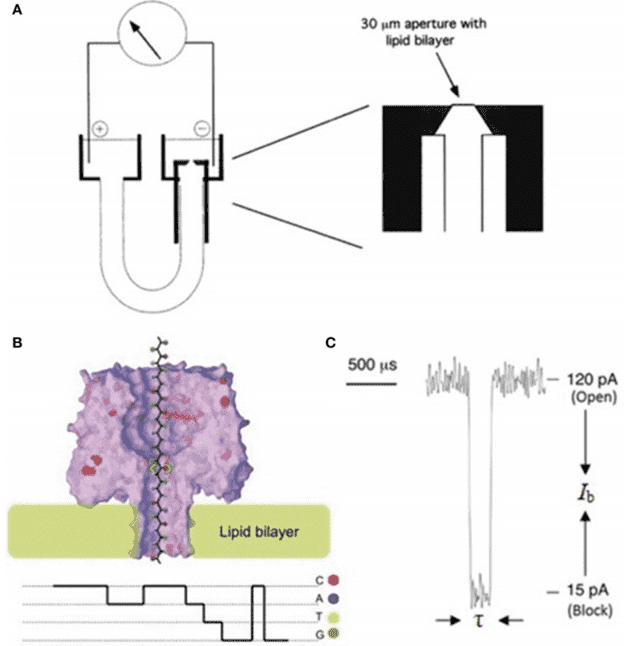 Figure 3. Schematic illustration of a nanopore sequencing device.
Figure 3. Schematic illustration of a nanopore sequencing device.
Nanopore sequencing represents a robust technology in the DNA sequencing field, producing incredibly long-read sequence data far cheaper and faster than was previously possible.
A major advantage of nanopore sequencing is the ability to produce ultra-long reads, and over 2 Mb read lengths have been achieved. The ultra-long read lengths are more likely to span entire regions of repetitive sequence and structural variation, offering a more complete view of genetic variations and the possibility to reconstruct complex genomes.
Traditional RNA sequencing approaches require the conversion of RNA to cDNA, which can introduce bias from reverse transcription or amplification. Nanopore sequencing can directly sequence RNA molecules, delivering unbiased, full-length and strand-specific RNA sequencing. The longest transcript sequenced by nanopore sequencing currently stands at over 20 kb in length. Direct RNA sequencing also brings the benefit of accurate measurement of poly-A tail length.
Targeted sequencing with a focus on specific genes/regions can provide relevant data, along with reduced cost, a higher depth of coverage and simplified data analysis. A range of targeted sequencing methodologies utilizing both PCR- and hybrid capture-based targeted enrichment strategies are available for nanopore sequencing, such as targeted panels and whole exome enrichment. Nanopore sequencing makes it possible to sequence much larger regions (including repetitive regions) in a single read.
Base modifications like 5mC and m6A are very important in gene expression and function. Epigenomics is a field to focus on base modifications. NGS techniques require additional processes, such as bisulfite treatment, for analysis of base modifications. However, nanopore sequencing that does not require PCR amplification or strand synthesis, can simultaneously detect both the base and its modification (including m6A, pseudouridine, 5mC and m7G) in the same sequencing run.
References:


