
We use cookies to understand how you use our site and to improve the overall user experience. This includes personalizing content and advertising. Read our Privacy Policy
Accept Cookies
The living world is composed of many different species, and these species are composed of many groups. Groups are composed of individuals who coexist in time and space. Individuals within a group show varying degrees of genetic variation, which is the result of sexual reproduction and the exchange of genetic material between individuals. Population structure (also called genetic structure and population stratification) refers to systematic differences in allele frequencies between subpopulations. In randomly mated populations, allele frequencies are expected to be roughly similar between populations. However, mating is often non-random to some extent, leading to the emergence of structures. Population structure results from physical isolation by distance or barriers, genetic drift, gene flow through migration, population bottlenecks and expansion, founder effects, evolutionary pressures, random chance, and cultural factors. Demographics is a complex phenomenon and no single measure can fully capture it. Understanding population structure requires a combination of methods and measures.
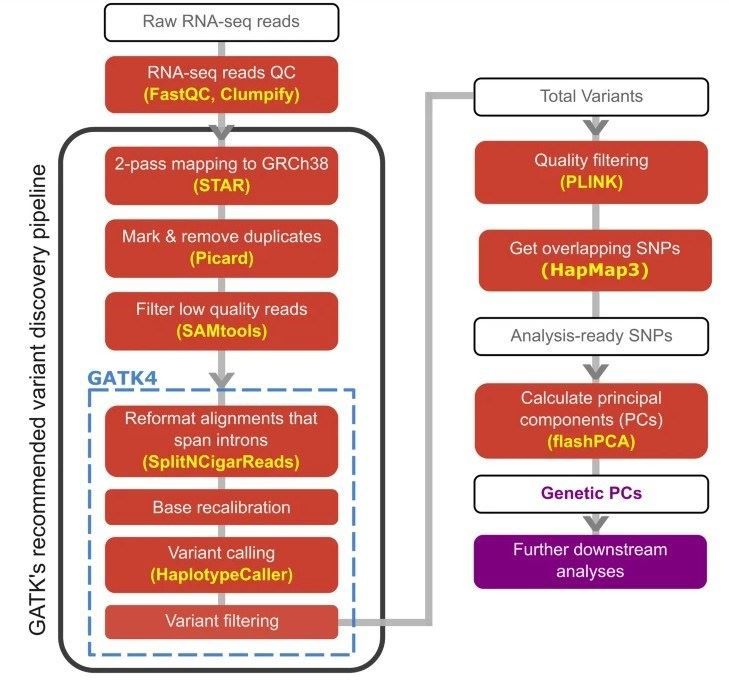 Fig. 1. The analysis pipeline used in this study, mainly following GATK's recommended variant discovery pipeline to call genetic variants from RNAseq samples. (Fachrul et al., 2023)
Fig. 1. The analysis pipeline used in this study, mainly following GATK's recommended variant discovery pipeline to call genetic variants from RNAseq samples. (Fachrul et al., 2023)
Although SNP arrays have been widely used to identify genetic variants, their results are limited by low probe density. High-throughput sequencing allows for improved characterization of genomic features and population structure at the whole genome level. Based on the NGS platform, CD Genomics offers whole genome sequencing of animals and plants to analyze genetic diversity, population structure, and selective characterization. Restriction site associated DNA (RAD) sequencing makes it possible to genotype thousands of SNPs. We offer RAD sequencing to address fine-scale population structures. In addition, we offer RNA sequencing (RNA-seq) to analyze genetic population structure. RNA-seq-based genotyping captures the genetic population structure of diverse but understudied animals and plants.
Using advanced statistical algorithms and bioinformatics tools, we analyze genomic data to identify patterns of genetic variation and infer population structure. Our analyses include methods such as principal component analysis (PCA), mixture analysis, and clustering algorithms to determine the genetic relationships and ancestral origins of individuals within populations.
We use high-throughput sequencing platforms to generate large-scale genomic data for population structure analysis. Our experienced scientists ensure that stringent quality control measures are taken to eliminate sequencing artifacts and biases and to ensure the reliability of the data generated. We provide intuitive visualization of population structure results, enabling researchers to easily interpret and understand genetic relationships between populations. Our comprehensive reports include detailed explanations of analytical methods and results, which aid in further research and decision-making processes.
Studying population genetic structure and diversity is fundamental to our understanding of biodiversity and species conservation. CD Genomics provides high-throughput sequencing technologies and sequencing genotyping methods to characterize natural population genetic structure, providing important insights into gene flow, genetic drift, and selection processes. If you are interested, please feel free to contact us.
Reference
Related Services
Agricultural NGS Services
Animal and Plant Whole Genome Sequencing
Transcriptome (RNA-seq) Services
SNP Detection
Bioinformatics Analysis Services
Genotyping By Sequencing (GBS)
 Send a Message
Send a MessageFor any general inquiries, please fill out the form below.
CD Genomics is propelling the future of agriculture by employing cutting-edge sequencing and genotyping technologies to predict and enhance multiple complex polygenic traits within breeding populations.


