DNA Barcoding is a cutting-edge method for species identification, leveraging a small segment of DNA from specific genes. This innovative molecular diagnostic technique enables swift, precise, and standardized species identification through the amplification of a short, standardized DNA segment. It has emerged as a focal point and a pioneering direction in the field of biological classification and identification.
By scrutinizing the sequences of these DNA fragments, a singular sequence can distinctly identify the species of an organism. The process bears resemblance to supermarket scanners that utilize the black stripes of a universal product code to differentiate products. However, unlike supermarket infrared scanners (FRID), DNA barcodes are decoded by sophisticated laboratory instruments and compounds.
With the technological backing of the Internet of Things and artificial intelligence, the future promises enhanced convenience in employing DNA bar scanning applications across various domains, including food safety, wild species diversity, and ecological environment protection. These DNA barcodes will play a pivotal role in identifying unknown species or components of organisms, such as wild mushrooms. This may involve cataloging taxonomic units in multiple locations, facilitating easy and rapid determination of species boundaries when compared with traditional biological taxonomy.
Upon acquiring the specimen, the researcher employs a small tissue sample to extract DNA. The isolated DNA fragments undergo amplification, replication, and subsequent sequencing, leveraging the advancements in DNA sequencing technology.
DNA sequencing entails determining the order of bases in a specific DNA fragment—namely, the four bases constituting the DNA molecule: A (Adenine), T (Thymine), C (Cytosine), and G (Guanine). (The human genome encompasses 3 billion base pairs, resulting in a sequence represented by these four letters.)
At the technical level, electrophoresis is a fundamental operation utilized. In this process, DNA fragments are placed at one end of a gel, and electrodes are applied to facilitate the passage of DNA through the gel (with smaller DNA molecules traversing faster). Consequently, the DNA molecules segregate into distinct bands. Researchers then analyze these bands to determine the sequence, a task now efficiently performed by automated machines such as capillary sequencers or slab gel machines.
A protocol for obtaining DNA barcodes. (Antil et al., 2023)
Advantages and Limitations of DNA Barcoding
DNA barcode technology relies on established standard operating procedures and a vast database, enabling rapid and accurate identification of species in large quantities. Unlike traditional identification methods, DNA barcoding doesn't demand extensive professional expertise and can be mastered quickly. It stands out for its simplicity, efficiency, and broad applicability. Given the inadequacy of traditional taxonomy for modern species identification, DNA barcoding employs shorter conserved gene sequences, extending its utility across diverse biological research.
However, the choice of the standard gene in DNA barcoding presents challenges. It must be conservatively conserved with primers that exhibit broad conservativeness for amplification across a wide range of species. Simultaneously, it needs sufficient variability to distinguish DNA sequences for species identification. In theory, there is no universally applicable DNA barcoding gene, as no single gene can maintain conservation across a diverse array of organisms while containing enough sequence variation for species discrimination. Consequently, different target genes must be identified for various species taxa.
Moreover, due to the abbreviated length of barcode genes and their limited number of differentiated bases, molecular identification through DNA barcoding is often accurate at the genus level. However, achieving precise species-level identification remains challenging. For finer species discrimination, genome sequencing becomes essential to compare a broader array of sequences.
Applications of DNA Barcoding
Animal Identification
Canadian zoologist Paul Hebert and colleagues conducted a comprehensive analysis of 13,320 mitochondrial cytochrome C oxidase subunit COI gene sequences across 11 phyla of the animal kingdom, encompassing vertebrates and invertebrates. Their findings revealed that differences in the DNA base sequences of a 648 bp fragment of this gene could be effectively utilized for taxonomic species identification. Intraspecific variation ranged from 0% to 2% for 98% of the species, with an average interspecific variation of 11.3%. The use of COI gene sequences as barcodes for identification proved highly effective across most animal groups.
Plant Identification
Primer pairs were meticulously designed using ITS sequences from closely related species. These primer pairs covered intervals such as ITS1, 5.8S rDNA, ITS2, and 26S rDNA. The ITS region, characterized by its short sequences (600-700 bp), connection of highly conserved regions at the ends, high copy number, length conservativeness, consistent evolution, and rapid evolution rate, is suitable for studying relationships within families, especially among related genera and species. It is also applicable for investigating relationships between populations.
Table 1 Common DNA barcode markers
Category
Gene/Marker
Animal
COI, Cytb, 12S rDNA, 18S rDNA
Plant
matK, rbcL, psbA-trnH, ITS
Bacteria
COI, rpoB, 16S rDNA, cpn60, tuf, RIF, gnd
Fungi
ITS, TEF1α, RPB1 (LSU), RPB2 (LSU), 18S (SSU)
Protists (Protozoa)
ITS, COI, rbcL, 18S rDNA, 28S rDNA
Identification of Microorganisms
Prokaryotes feature three types of ribosomal DNA—23S, 16S, and 5S—directly involved in protein translation. The 16S rDNA has become a standard for systematic classification due to its informativeness and moderate sequence size (1.5K). Bacteriologists generally accept that when 16S rDNA sequence homology exceeds 97%, it signifies homology within the genus. Internal transcribed spacer 1 (ITS1), 5.8S rRNA gene (5.8 S rDNA), internal transcribed spacer 2 (ITS2), and 28S rRNA gene (28S rDNA) collectively referred to as ITS, provide valuable information for studying phylogenetic relationships within genera, between related genera, and even within families.
Table 2 Key DNA barcode library databases for different phyla
Phylum
DNA Barcode Library Databases
Markers
Bacteria and Archaea
RDP (Ribosomal Database Project)
Small subunit rRNA sequences
SILVA Database
Ribosomal RNA (rRNA) gene datasets
Eukaryotic Microorganisms
UNITE Database
Internal Transcribed Spacer (ITS) region for fungi
ITS2 Database
ITS2 region for fungi, plants, and some protists
As the volume of sequencing data continues to grow, researchers have synthesized this information into databases, giving rise to DNA barcode libraries designed for the identification of diverse phyla. Notable examples include the RDP and SILVA databases, instrumental in identifying bacteria and archaea, as well as the UNITE and ITS2 databases, tailored for the identification of eukaryotic microorganisms. As research progresses, the exploration of additional DNA barcode markers and databases is expected to expand.
Reference
Antil, Sandeep, et al. "DNA barcoding, an effective tool for species identification: a review." Molecular Biology Reports 50.1 (2023): 761-775.
For research purposes only,
not intended for clinical diagnosis, treatment, or individual health assessments.
For any general inquiries, please fill out the form below.
We provide the best service according to your needs Contact Us
PDF Download
×
OUR MISSION
CD Genomics is propelling the future of agriculture by employing cutting-edge sequencing and genotyping technologies to predict and enhance multiple complex polygenic traits within breeding populations.
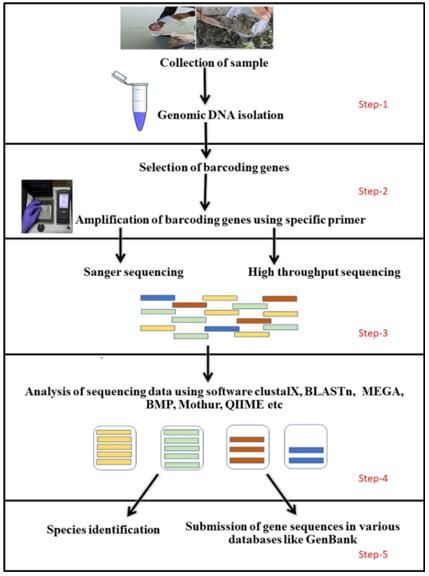 A protocol for obtaining DNA barcodes. (Antil et al., 2023)
A protocol for obtaining DNA barcodes. (Antil et al., 2023)