We use cookies to understand how you use our site and to improve the overall user experience. This includes personalizing content and advertising. Read our Privacy Policy


Tell Us Your Project
We are dedicated to providing outstanding customer service and being reachable at all times.
Long Read Sequencing for Population Genetics
Population genetics is the study of the genetic composition of populations, including the distribution and variation of genotype and phenotype frequencies in response to natural selection, genetic drift, mutation, and gene flow processes. In recent years, continuing advances in sequencing technology and bioinformatics have paved the way for the realization of population-scale long read sequencing. As a leading global life sciences company, CD Genomics' long read sequencing solutions provide accurate and continuous DNA sequences, including structural variation and epigenetic insights, for population genetics studies.
Introduction to Population Genetics
Population genetics is a field of biology that studies the genetic composition of groups of organisms and the changes in genetic composition that result from the action of various factors such as natural selection. It aims to understand the processes that shape the genetic composition of populations and allows the examination of the effects of genetic variation on the health of individuals, as well as the role of genetics in the development of complex traits, such as susceptibility to certain diseases. Population genetics studies typically rely on large genomic datasets, often combining microarray, exome, and genomic data to obtain the desired results. However, current short-read next-generation sequencing (NGS) methods are unable to detect variants in dark regions and often encounter large or complex variants, which may differentially affect the acquisition of genetic insights from ancestral populations and may lead to a partial or incomplete understanding of genetic causes and disease mechanisms. The advent of long-read sequencing Sequencing has revolutionized the field and significantly changed the game for population genomics projects.
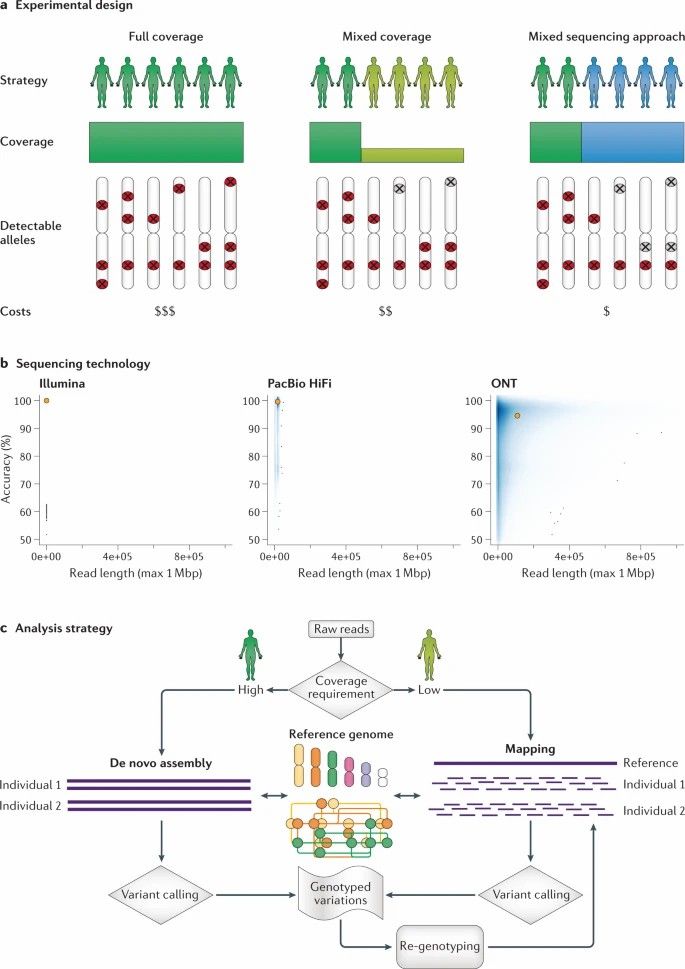 Fig. 1. Overview of long-read population study design. (De Coster et al., 2021)
Fig. 1. Overview of long-read population study design. (De Coster et al., 2021)
Solutions Offering at CD Genomics
Our advanced long read sequencing platforms, PacBio SMRT sequencing and ONT Nanopore sequencing enable creat differentiated population sequencing datasets that extend far beyond the limitations of short-read systems. CD Genomics is committed to providing specialized long read sequencing solutions for population genetics research, aiming to revolutionize precision health programs and disease research.
We offer flexible genome coverage options and targeted solutions that enable you to maximize the output of your research budget while achieving optimal long read coverage to gain insights from the population to the individual level. Our long read sequencing technology provides trusted solutions for the following population genetics studies:
- Comprehensive Variant Detection
One of the key aspects of population-scale genetics studies is the ability to accurately detect genetic variation across the genome. Short-read sequencing methods often struggle with challenging regions, such as highly repetitive or homologous regions. In contrast, our long read sequencing technology excels in these regions, enabling comprehensive variation detection. This means we can provide a more complete picture of genetic variation within a population, including small variants (SNVs and insertion deletions) as well as larger structural variants (SVs).
- Complex Genomic Regions Detection
Certain disease-associated genes, such as SMN1, LPA, HBA, HBB, and HBM, present challenges for variant detection due to their homologous sequences, copy number variation (CNV), and gene fusions. These genes are associated with diseases such as spinal muscular atrophy, lipoprotein (a) levels, thalassemia, and sickle cell disease, which occur in diverse populations. Our long read sequencing technology can unravel these complex genomic regions to provide a more accurate and comprehensive understanding of these diseases and their genetic basis.
- Phased and Haplotype Analysis
Phasing variants and determining haplotypes are critical to understanding the genetic structure of populations and identifying disease-associated variants. Our long read sequencing solutions can accurately phase variants in larger genomic regions, providing insight into the allele combinations on each chromosome. This information is invaluable for population genetics studies, as it enables the identification of population-specific variants and haplotypes that may be associated with disease susceptibility or treatment response.
- Genome-Wide Methylation Analysis
In addition to variant detection and haplotype analysis, our long read sequencing technology offers the unique advantage of genome-wide methylation analysis. DNA methylation plays a key role in gene regulation and can influence the onset and progression of disease. By combining methylation data with genetic variant information, we can gain a deeper understanding of the epigenetic factors that influence population health and disease susceptibility.
Advantages of Our Long Read Sequencing Solutions for Population Genetics
- Create population-specific reference genomes with high completeness, correctness and continuity.
- Provide fixed-phase genomes with high accuracy, completeness, and resolution for all variant classes.
- Cover challenging and repeat-heavy regions.
- Genome-wide methylation status for multi-omics studies.
CD Genomics is committed to providing accurate, comprehensive, and high-resolution long read sequencing solutions to accelerate population genetics research. We aim to help researchers build diverse population health databases and understand biological, environmental, and lifestyle influences on human health. If you have any questions, please feel free to contact us. We look forward to working with you on projects of interest.
Reference
- De Coster, Wouter, Matthias H. Weissensteiner, and Fritz J. Sedlazeck. "Towards population-scale long-read sequencing." Nature Reviews Genetics. 22.9 (2021): 572-587.
Related Services
PacBio SMRT Sequencing
Oxford Nanopore Sequencing
Population Evolution
Human Whole Genome Sequencing
Human Genome Structural Variation Detection
Genome-Wide Association Study (GWAS)
For Research Use Only. Not for use in diagnostic
procedures.
Talk about your projects
For research purposes only, not intended for personal diagnosis, clinical testing, or health assessment