Single-cell ATAC-Seq Introduction
ATAC-seq, short for Assay for Transposase-Accessible Chromatin using sequencing, is a method developed by the laboratories of William J. Greenleaf, Jason Buenrostro, and Howard Y. Chang at Stanford University in 2013. It is used to study chromatin accessibility, which is often understood as the openness of chromatin. The principle of ATAC-seq involves the easy binding of the transposase Tn5 to open chromatin, followed by sequencing of the DNA sequences captured by the Tn5 enzyme.
Each of our cells contains two meters of DNA tightly packed within the microscopic nucleus. ATAC-seq identifies which parts of the DNA are accessible, allowing proteins to approach and regulate them. Genes are regulated by many different proteins. For example, transcription factors bind to DNA and initiate reading. There are countless transcription factors, each recognizing and binding to highly specific DNA sequences. These sequences are called motifs, and they can be marked in ATAC-seq data because of their specificity. This technology is widely used in the genomics field, such as the Human Cell Atlas project, to understand and map genome function. However, the complex and time-consuming process of ATAC-seq yields reliable results from only a small fraction of cells.
ATAC-seq provides a comprehensive map of open chromatin across the entire genome and can be used to investigate transcription factor binding, gene expression regulation, and other biological processes. By comparing changes in open chromatin maps at different developmental stages or under different experimental conditions, specific biological mechanisms can be further explored, such as the stages of embryonic development or the variations in open chromatin maps between tumor and normal tissues.
Our Single-cell ATAC-Seq Service
CD Genomics offers the Chromium Single-Cell ATAC Solution developed by 10X Genomics, which provides a comprehensive and scalable method to study and analyze the chromatin accessibility in hundreds to thousands of cells within a single sample. The solution involves the use of a transposase to fragment the nuclear DNA in a mixed-cell suspension. The nuclei are then encapsulated into droplets using a microfluidic chip, forming nanoscale gel bead-in-emulsion (GEMs). With the addition of 10X barcodes, each DNA fragment resulting from the cleavage of individual nuclei is labeled with a unique barcode. Through library construction and sequencing, the sequenced reads are associated with each individual nucleus based on the 10X barcodes.
Single-cell ATAC-Seq Workflow
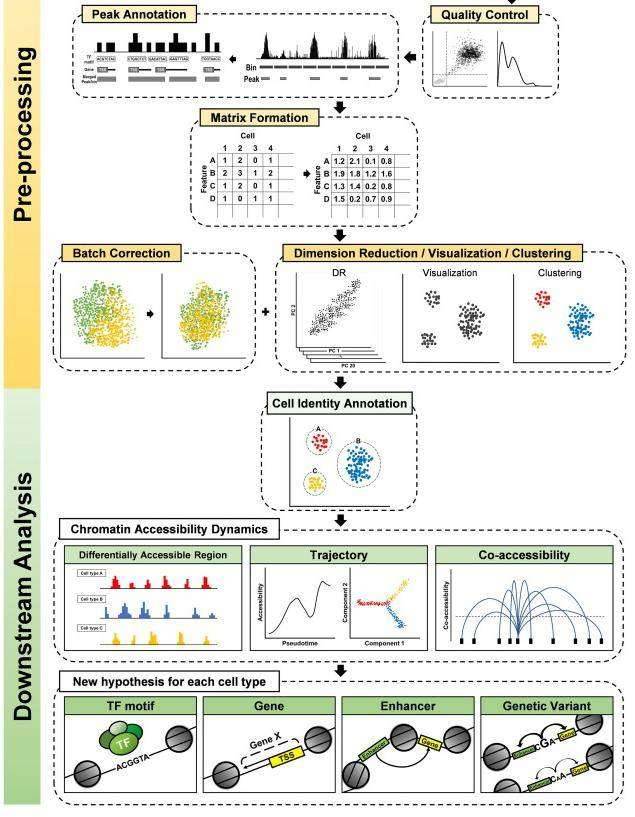 (Seungbyn Baek et al,. Computational and Structural Biotechnology Journal 2020)
(Seungbyn Baek et al,. Computational and Structural Biotechnology Journal 2020)
Transposase Cleavage of Nuclear DNA
The cell nuclei suspension is incubated in a mixture containing transposase. The transposase enters the nuclei and preferentially fragments the DNA in open chromatin regions. At the same time, sequencing adapter sequences are added to the ends of the fragmented DNA fragments.
GEM Generation and Barcode Addition
On the Chromium Next GEM Chip H, gel beads containing barcodes, transposase-cleaved nuclei, the mixture (including ATAC buffer and ATAC enzyme), and oil droplets are mixed to generate GEMs. To ensure that each droplet contains a single nucleus, the nuclei need to be diluted in a controlled manner, ensuring that the majority of the generated GEMs (~90-99%) do not contain nuclei, while the remaining GEMs contain a single nucleus.
After GEM generation, the gel beads dissolve, releasing oligonucleotides containing (i) the Illumina P5 sequence, (ii) a 16-nt 10X barcode sequence, and (iii) the Read 1 (Read 1N) sequence. These nucleotide sequences are mixed with the fragmented DNA and the mixture. Subsequent thermal cycling generates single-stranded DNA containing the 10X barcode. After incubation, the GEMs are subjected to oil breakage, and the single-stranded DNA containing the 10X barcode from all GEMs is mixed and recovered together.
Purification
Silane magnetic beads are used to remove residual biochemical reagents from the oil breakage reaction mixture. Solid Phase Reversible Immobilization (SPRI) beads are employed to eliminate unused 10X barcodes from the sample.
Library Construction and Quality Control
PCR is performed to add P7 adapters and sample-specific index tags (Index N) to both ends of the library, resulting in a library containing P5 and P7 adapter sequences for Illumina bridge PCR amplification.
Recommended Sequencing Depth and Parameters
| Indicator | Parameter |
|---|---|
| Sequencing Depth | 25,000 read pairs per cell nucleus |
| Sequencing Type | PE150, dual-index sequencing |
Single-cell ATAC-Seq Service Advantages
- Streamlined Process and Fast Turnaround: Enables detection of chromatin accessibility in single-cell transcriptional regulatory regions.
- High Throughput: 500-10,000 cell nuclei per channel.
- High Efficiency: Cell nucleus capture rate of up to 65%.
- Wide Applicability: Validated for use with primary cells, cryopreserved cells, fresh tissues, etc.
- Information Analysis: Provides large amounts of data for in-depth analysis of single-cell gene regulatory networks.
- Integration of Data: Allows simultaneous sequencing of single-cell ATAC, mRNA, TCR/BCR from the same sample, and integration of the data.
Sample Requirements
- Types: Fresh tissues, primary cells, cell lines, etc.
- Sources: Blood extraction, magnetic bead enrichment, flow cytometry enrichment, tissue dissociation, etc.
Sample Quantity and Other Quality Control Requirements:
| Sample Type | Sample Quality Control Requirements |
|---|---|
| Cell Suspension | >1x105 cells; >80% viability; concentration: 500-1,000 cells/μl; < 5% cell aggregation; no cell fragments or other particles larger than 40 μm; absence of reverse transcription inhibitors and non-cellular nucleic acid molecules. |
| Blood | >5 ml of whole blood collected in EDTA anticoagulant (heparin anticoagulant not acceptable). |
| Tissue | Fresh tissue measuring 0.3 cm × 0.3 cm (not exceeding 0.5 cm × 0.5 cm) in size, 4-5 pieces. |
Single-cell ATAC-Seq Application
Study cellular heterogeneity
Explore biomarkers
Define cell types
Construct gene regulatory networks